


前段时间,我在整理RSS订阅的时候发现一位博友的友联订阅不到了。当时我就蒙了,该不会又有博友跑路了吧。后来看了之后才发发现,这位朋友把RSS给关闭了。这样我就很难受了,订阅不到最新的动态,也没有邮件提醒。
之后我就想着不行就用第三方网站订阅一下,或者自己写个脚本爬取一下重要信息做个rss,毕竟有rsshub这样的开源程序,搞起来也方便。
之后突然发现FreshRSS可以采用HTML+Xpath的方式对文章进行爬取,和第三方网站原理差不多。也是就测试可以一下效果,这里先记录一下重要的点,再讲一下我发现的问题。
因为是采用HTML+Xpath的方式获取订阅,所以需要具有一定的Xpath语法基础 XPath 1.0
流程
这里以我友联中的一位博友 Nibbles Blog - 半字节博客 举例,如果本人觉得有被冒犯到,请及时联系我。
更改HTML+Xpath模式
在添加feed源页面,有一个选择Feed源类型,默认是关闭的,我们需要打开,并选择 HTML + XPath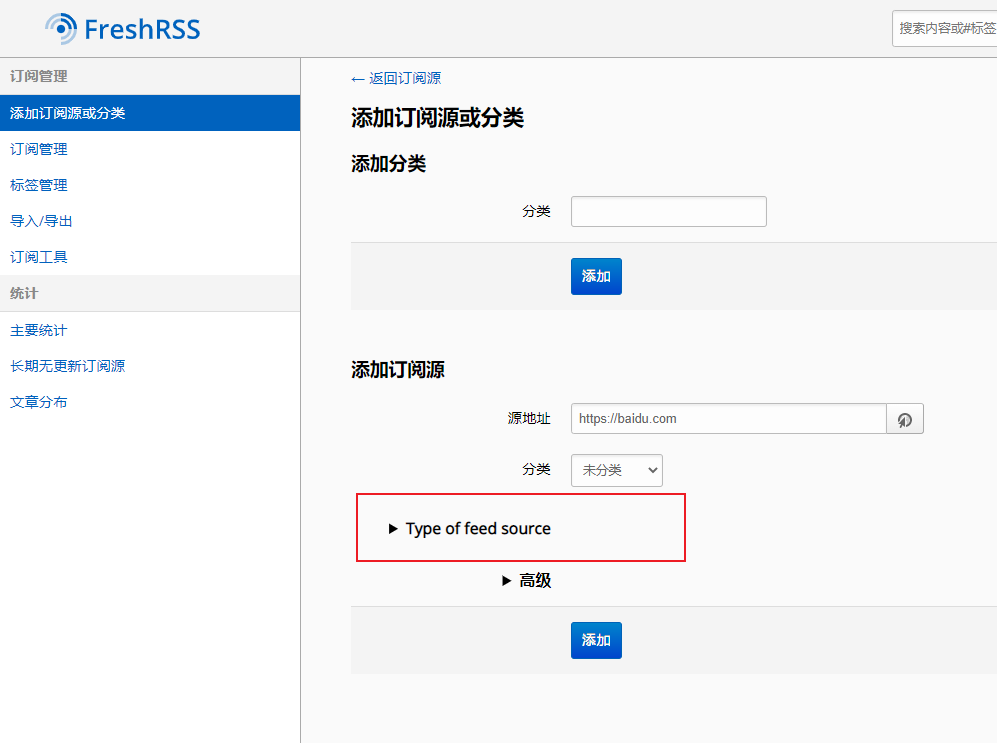
选择网站标题
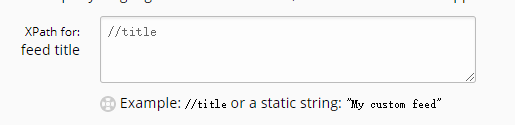
这里选择的标题是订阅链接的名称,也就是网站的名称,一般来说保持默认就可以。
选择订阅内容区域
这里需要XPATH能够获取到能看到的所有文章块,一开始没搞懂,只选择了一篇,导致只能获取到一篇内容。这样如果连续更新了多篇文章,是会有遗漏的。
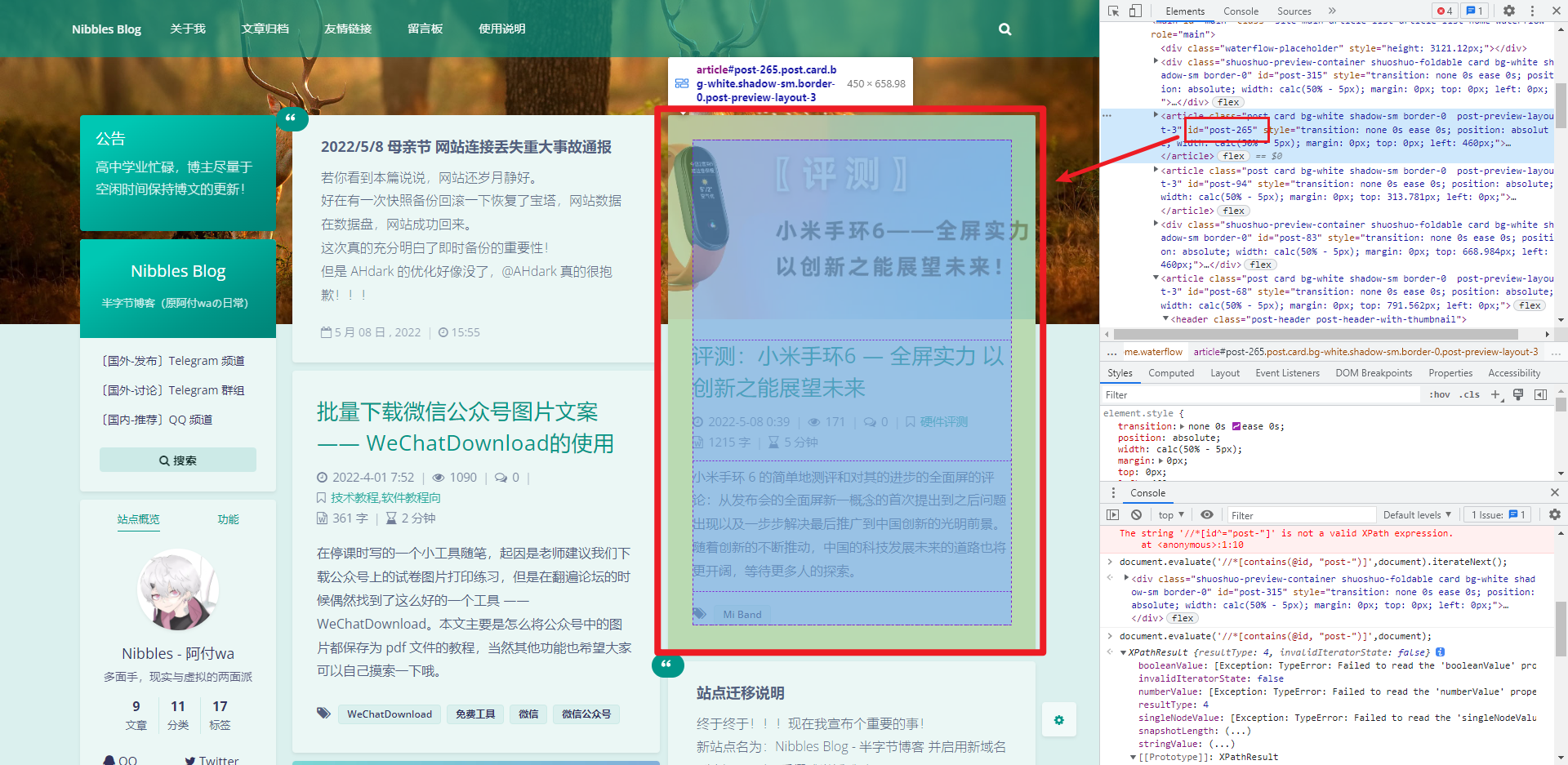
这里有id,正好就用来进行模糊匹配了。

选择文章标题
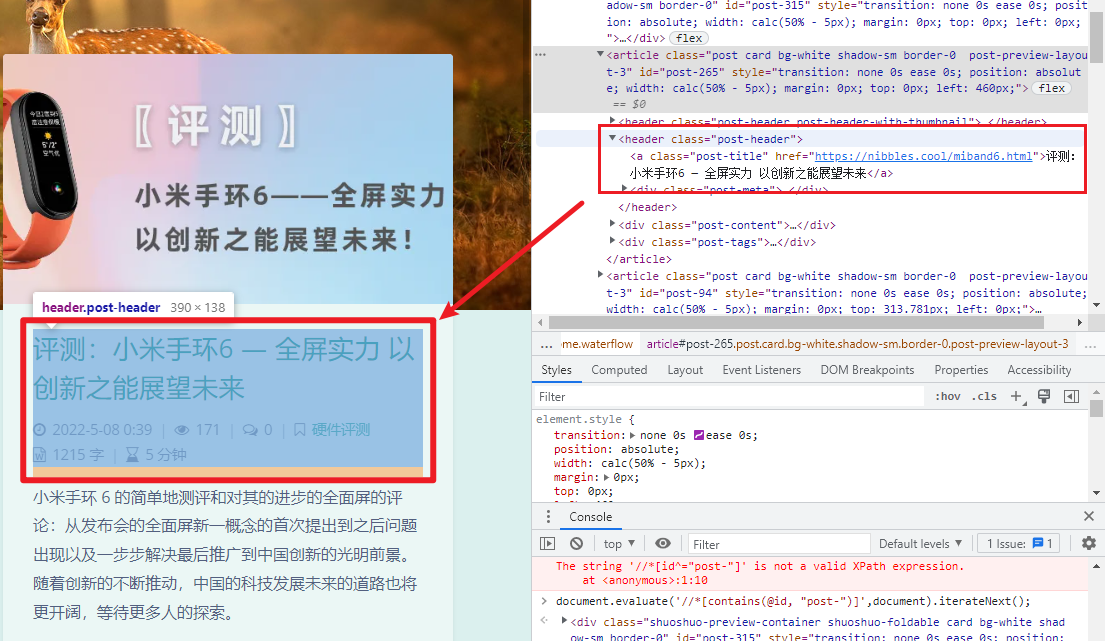
这里标题的class在文章区域之中是唯一的,所以就用这个class来锁定标题。

根据网页提示,如果是在文章区域块内选择元素,前面需要添加 descendant::选择文章内容


选择文章链接
文章标题和链接在一个标签之中,根据页面提示,我们只需要先选择到链接上,再选择链接属性即可

选择链接时间
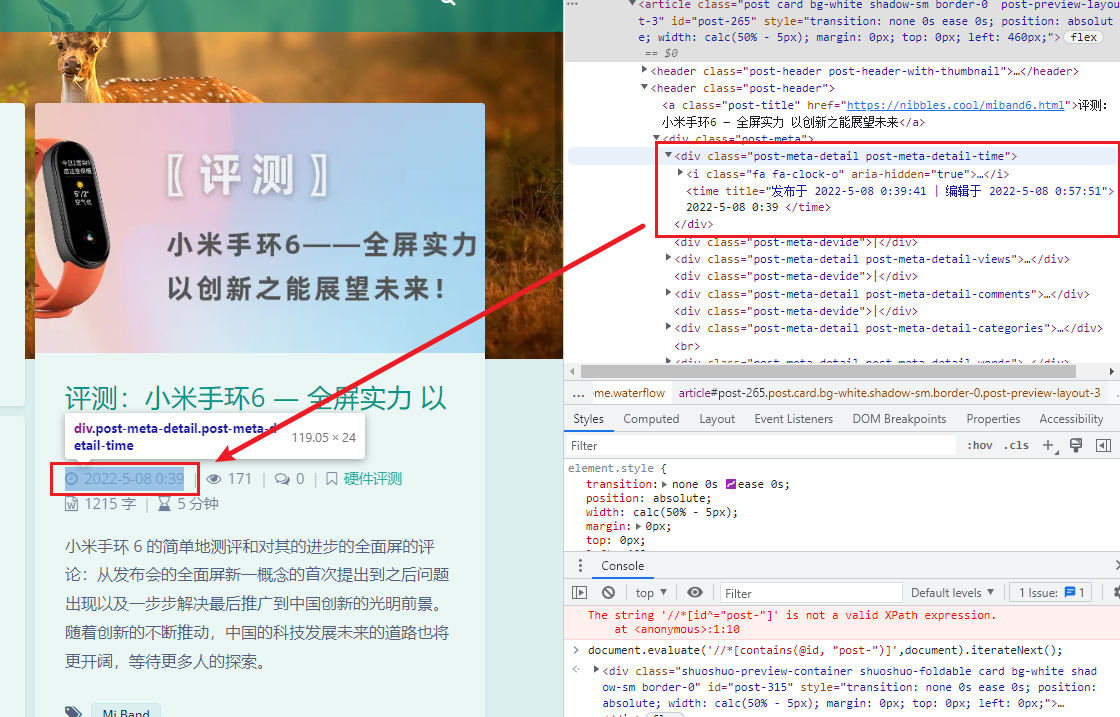
这里因为time标签没有唯一的可以选择的,所以我先选择了更大范围的div,再锁定了时间

有了以上几个就够用了,当然官方还提供了缩略图和标签的选择。这个我还没研究透,就先不搞了。
一些问题
- 添加过程中最大的问题还是Xpath语法的运用,因为没有系统学习过,所以就是用到什么再去看一下支不支持
- 缩略图,我之后添加了,但是界面没有什么变化,还不知道是怎么使用
- 时间会被PHP的时间格式化函数处理掉,但是有些网站的时间真的不知道会处理成什么样子,有可能处理失败,采用采集时的时间
最后说两句
FreshRSS可以试一下,之后会探索更多的用法。Xpath语法在处理网页的时候用到的地方也挺多的,之前一直以为Chrome自带的会省去很多麻烦,但是真正用的时候会发现自带的永远满足不了需求,还是需要进行语法的学习。
我都是通过博客朋友圈自动采集订阅~
这是什么呀
感谢ncc提供的解决方案,的确如 @火喵酱 说的一样出于对网站内容的保护关闭了rss;同时可能想到有部分网友会想ncc一样希望使用rss订阅博客以便收到最新文章,所以我希望能否转载贵站网站(当然会注明原作者原出处)
没有问题
对这块不太懂,但是前段时间想着找那种可以聚合友链朋友们的网页订阅器
自己的需求,如果是自己用,使用tinytinyrss或者fresh-rss这种就可以,如果作为一个独立页面存在,可以看一下这个项目。https://idealclover.top/archives/634/
这种方式处理的确实会遇到各种各样的问题,本来学文章那段时间我打算看一下的,结果文中测试的作者主题一直换,就没有兴趣了。这些不支持的站点,有时间统一再去看一下更新动态吧。
我也不理解为什么要关rss啊
如果是一些经验技术分享的博客,确实有很多百家号之类的各种盗,关闭rss会增加一点被“搬运”的门槛。
确实,查资料结果csdn全都是采集文,太恶心了
最离谱的是,有一半的csdn文章被搞成文件,然后还要付费下载,真的恶心。我最近在找插件看看能不能把这些黑名单网站给屏蔽了